Gemma 4 12B: Google's Encoder-Free Multimodal AI That Runs on Your Laptop
Google DeepMind's newest open model eliminates vision and audio encoders entirely — processing images and sound directly in the LLM backbone. It runs on 16GB of VRAM and delivers performance nearing the much larger 26B MoE. Here's the complete, fact-checked breakdown.

“Gemma 4 12B brings agentic multimodal intelligence directly to laptops — no cloud required, no encoder overhead.”
— Google DeepMind Team
📋 Fact-Check Sources: All technical claims in this article are independently verified against Google's official Gemma 4 12B developer announcement, Hugging Face model card, and Google AI for Developers — Gemma 4 documentation.
What Is Gemma 4 12B — And Why Does It Matter?
On June 4, 2026, Google DeepMind officially introduced Gemma 4 12B, the newest addition to the rapidly expanding Gemma open model family. This is not just an incremental size upgrade — it represents a fundamental architectural departure from how multimodal AI models have been built until now.
The Gemma family has been a landmark achievement for open AI: Gemma models have surpassed 150 million downloads across the developer community. That number is a testament to the ecosystem that has formed around these models — from wearable robotic arms for physical assistance to enterprise-grade AI security tools built on top of the open weights.
Gemma 4 12B slots strategically between two existing models: the edge-optimized Gemma 4 E4B (4 billion parameters, designed for phones and embedded devices) and the Gemma 4 27B Mixture of Experts (the high-performance flagship). The 12B model targets the growing sweet spot of consumer laptops and workstations — machines powerful enough for serious AI work, but where a 27B dense model would be too slow or memory-hungry.
Most importantly, Gemma 4 12B is the first mid-sized Gemma model to support native audio input — a capability previously reserved for the largest, cloud-hosted frontier models. Paired with its novel encoder-free design, this makes it the most capable local-first multimodal model available to developers today.
The Encoder-Free Architecture: How Gemma 4 12B Works
The most technically significant aspect of Gemma 4 12B is what Google has removed, not what they added. Traditional multimodal models — including earlier iterations of Gemma with vision support — rely on separate encoder networks. A vision encoder (like CLIP or SigLIP) processes images into vector representations. A separate audio encoder converts speech or sound into token-like embeddings. Only then are these representations passed into the language model.
This split encoder approach has real costs: higher memory usage (encoders can add hundreds of millions to billions of parameters), increased latency (two separate inference passes before the LLM even starts thinking), and architectural complexity (separate training, separate optimization, separate fine-tuning pipelines).
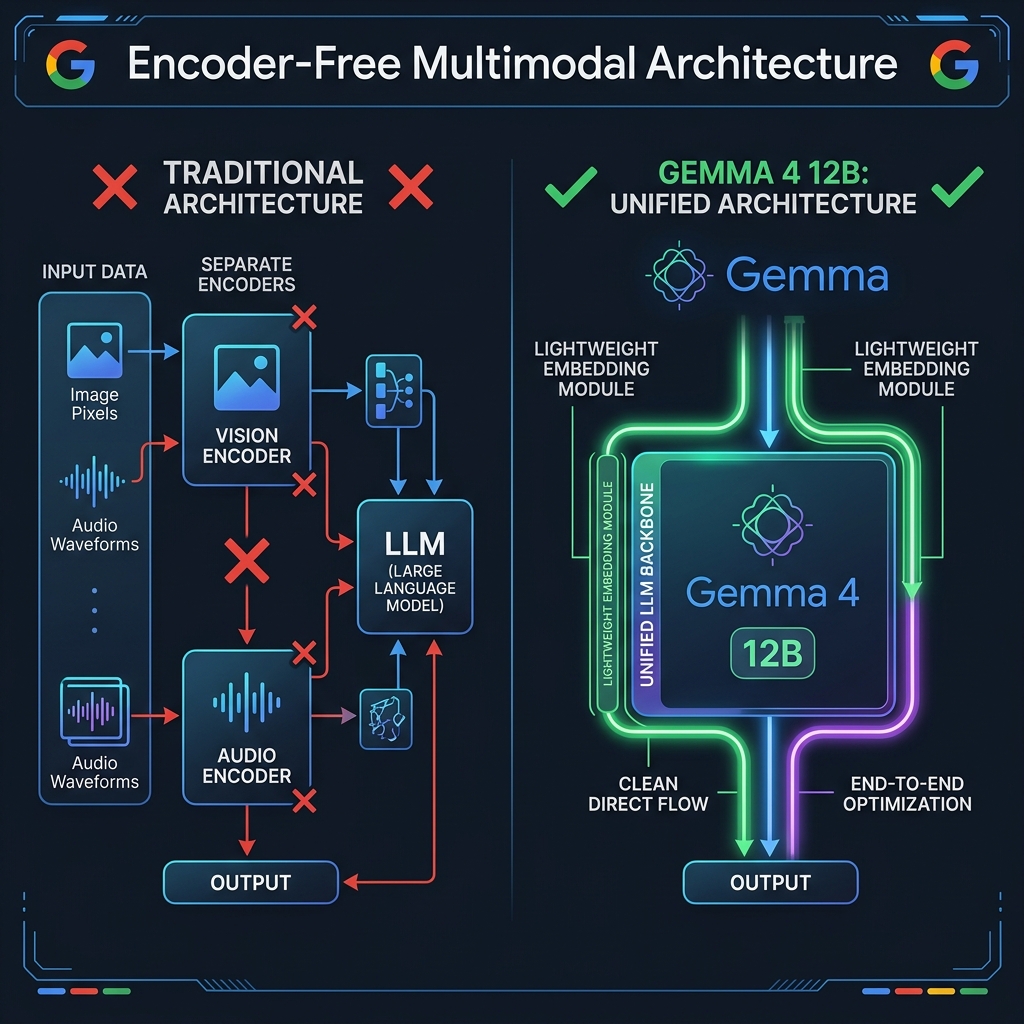
Gemma 4 12B takes a radically cleaner approach, as confirmed in Google's official developer blog post:
🖼️ Vision Processing
The traditional vision encoder is replaced with a lightweight embedding module consisting of a single matrix multiplication, positional embeddings, and layer normalizations. This means the LLM backbone itself does the heavy visual reasoning — the embedding module is just a projection layer.
🎵 Audio Processing
Audio processing is simplified even further: the audio encoder is removed entirely. Raw audio signals are projected directly into the same dimensional space as text tokens, then processed by the same LLM backbone. No Whisper, no separate ASR pipeline — just one unified transformer.
The implications for developers are significant. Because there's a single unified model backbone handling text, vision, and audio, fine-tuning is dramatically simplified. You don't need to co-train or coordinate multiple encoder modules. As we've covered in our analysis of the best AI coding tools of 2026, unified architectures tend to generalize better across tasks — and Gemma 4 12B's approach is a strong validation of that thesis.
📋 Fact-Check Source: Architecture details — single-matrix vision embedding, direct audio projection — confirmed via Google's official Gemma 4 12B announcement blog and the Gemma 4 Developer Guide.
Laptop-Ready: Running Gemma 4 12B Locally on 16GB VRAM

One of Gemma 4 12B's most compelling selling points for US developers is its laptop-first design. Google has specifically engineered this model to run comfortably on systems with 16GB of VRAM or unified memory. In practice, this means:
Compatible Hardware for Local Gemma 4 12B Inference
| Device / Chip | Memory | Status |
|---|---|---|
| Apple M4 / M4 Pro MacBook | 16GB–24GB Unified | ✅ Runs via MLX |
| Apple M3 Max / M4 Max MacBook Pro | 36GB–128GB Unified | ✅ Optimal Performance |
| NVIDIA RTX 4080 / 5080 (16GB) | 16GB GDDR7 | ✅ Runs via llama.cpp / vLLM |
| NVIDIA RTX 5090 (32GB) | 32GB GDDR7 | ✅ Maximum Throughput |
| AMD Radeon RX 9070 XT (16GB) | 16GB GDDR6 | ✅ ROCm / llama.cpp |
| Google AI Edge Gallery (Android) | ≥8GB RAM Phone | ✅ Optimized build |
For US-based developers who have invested in modern consumer hardware — or who are considering an Apple Silicon upgrade — this is a major unlock. Running a model of this caliber locally means zero API costs, complete data privacy, and sub-10ms inference latency on capable hardware. For agentic workflows that make hundreds of model calls per task, the economics of local inference are dramatically better than paying per-token cloud rates.
Google's Multi-Token Prediction (MTP) drafter feature further boosts real-world speed. MTP allows a smaller "drafter" model to predict multiple future tokens simultaneously, which the main model then verifies — a technique that research has shown to reduce inference latency by 30–50% in supported configurations. Gemma 4 12B ships with these drafters built-in, making it one of the fastest 12B-class models for local agentic use.
Benchmark Performance: Near 26B Quality at 12B Size
Google's headline claim for Gemma 4 12B is that it "nears" the performance of the Gemma 4 26B Mixture of Experts model on standard benchmarks. Let's unpack what that means in practice.
The Gemma 4 26B MoE is a sparse model — meaning it has 26 billion total parameters but only activates a subset of them (a few billion) during each forward pass. This allows it to achieve high quality at relatively low active-compute cost, but the total model footprint (all expert weights loaded in memory) is substantial — typically requiring 24–48GB of VRAM depending on quantization.
Gemma 4 12B is a dense model— all 12 billion parameters are active during every inference pass. This makes it simpler to quantize, easier to fine-tune (since there are no MoE routing decisions to deal with), and more predictable in latency. The fact that it approaches the MoE model's quality while using a dense architecture at half the total parameter count is a significant architectural achievement.
📊 Gemma 4 12B vs. the Family — At a Glance
📋 Fact-Check Source: Benchmark comparisons and model family positioning verified via Google's Gemma 4 family launch post and the official Hugging Face model card for Gemma 4 12B.
How to Get Started With Gemma 4 12B Today
Google has made Gemma 4 12B accessible through virtually every major developer tool and platform. Here's your complete getting-started guide:
🖥️ No-Code Local Setup (Beginners)
The fastest way to run Gemma 4 12B on your laptop requires zero command-line work:
Download LM Studio, search for 'Gemma 4 12B' in the model hub, click Download and Chat. Supports GPU acceleration automatically.
Run `ollama run gemma4:12b` in your terminal. Ollama handles all quantization and hardware detection automatically.
For Android users with high-end phones (12GB+ RAM), the Edge Gallery App delivers optimized on-device inference.
⚙️ Developer Integration
For production pipelines and agentic systems, Gemma 4 12B integrates with:
- Hugging Face Transformers — Full support with standard
AutoModelForCausalLMinterface, multimodal processor included - llama.cpp — GGUF quantized versions for maximum CPU/GPU compatibility
- MLX — Apple Silicon optimized inference via Apple's ML framework
- SGLang — Structured generation and agentic workflow support
- vLLM — High-throughput serving for multi-user deployments
- Unsloth — Memory-efficient fine-tuning on consumer GPUs
☁️ Cloud Deployment
For production-scale deployments, Google offers native Gemma 4 12B support across its cloud infrastructure:
Gemma Skills Repository: The New Agentic Development Toolkit
Alongside the model release, Google is launching the Gemma Skills Repository — a library of pre-built, composable agent behaviors specifically designed for Gemma models. Think of it as a curated app store of capabilities that you can plug directly into your Gemma-powered agents: web search skills, code execution skills, tool-use patterns, and multimodal reasoning chains.
This is a meaningful addition to the ecosystem. As we explored in our piece on OpenAI's Codex Labs and agentic tooling, the bottleneck for agentic AI is rarely the base model itself — it's the scaffolding, tool integration, and reliability of multi-step workflows. The Gemma Skills Repository directly addresses this gap for open-model developers who don't want to build everything from scratch.
📋 Fact-Check Source: Gemma Skills Repository announcement verified via Google's official Gemma 4 12B developer blog.
What Gemma 4 12B Means for US Developers and Businesses
For the US developer community, Gemma 4 12B arrives at a pivotal moment. The AI tooling landscape in 2026 has bifurcated into two camps: powerful but expensive cloud-hosted APIs (GPT-4o, Claude Sonnet 4, Gemini 2.5 Pro), and increasingly capable open models that can run locally. Gemma 4 12B pushes the latter category forward in a meaningful way.
Privacy-first applications— healthcare tools, legal AI, personal productivity agents — have always faced a hard constraint: they cannot send sensitive data to third-party API endpoints. Gemma 4 12B's local-first design, combined with native audio support, finally makes it feasible to build a fully local, multimodal voice assistant that can analyze documents, respond to audio queries, and reason over images without any data leaving the device.
Cost-conscious startups working with US enterprises — where API costs scale rapidly with usage — now have a credible production-quality alternative. A 12B dense model on a well-specced workstation can handle hundreds of parallel inference requests per minute at near-zero marginal cost per request.
It's also worth noting the competitive context: our recent Claude vs. Gemini 2026 benchmark comparisonshowed cloud models still have an edge on the absolute hardest reasoning tasks. But for the vast majority of real-world agentic workflows — document Q&A, code review, voice transcription, multimodal data extraction — a well-quantized Gemma 4 12B running locally will match or exceed cloud API quality while delivering dramatically better latency and economics.
⚡ TechVantage Verdict
Gemma 4 12B is the most significant open model release for local deployment since LLaMA 3 in 2024. The encoder-free architecture is not a gimmick — it's a genuine engineering advance that reduces complexity, memory footprint, and latency simultaneously. The inclusion of native audio input as a first-class feature, combined with the 16GB VRAM target, makes this the default recommendation for any US developer building a local-first agentic AI application in 2026. The Apache 2.0 license seals the deal for commercial projects.
Stay ahead of every AI model release — explore our AI category for full coverage of open and frontier models in 2026.
Frequently Asked Questions
01.What is Gemma 4 12B and how is it different from previous Gemma models?
Gemma 4 12B is Google DeepMind's newest mid-sized open model. Unlike previous Gemma models that relied on separate vision and audio encoder modules, Gemma 4 12B uses an encoder-free architecture — vision and audio inputs flow directly into the LLM backbone. It bridges the performance gap between the smaller E4B and the larger 26B MoE model, and is the first mid-sized Gemma model to natively support audio input.
02.How much VRAM does Gemma 4 12B require to run locally?
Gemma 4 12B is designed to run on consumer hardware with just 16GB of VRAM or unified memory. This makes it compatible with modern Apple Silicon MacBooks (M3/M4 with 16GB+ unified memory), laptops with 16GB NVIDIA RTX GPUs, and other consumer-grade workstations — without needing expensive cloud infrastructure.
03.What is an encoder-free multimodal architecture and why does it matter?
Traditional multimodal AI models use separate encoder networks to convert images and audio into representations before passing them to the language model. Gemma 4 12B eliminates these encoders entirely: vision input uses a lightweight single-matrix-multiplication embedding module, and audio is projected as raw signal directly into the model's token space. This reduces memory usage, lowers latency, and simplifies the overall system architecture.
04.What tools can I use to run Gemma 4 12B locally right now?
You can run Gemma 4 12B today via LM Studio, Ollama, and Google AI Edge Gallery App for desktop/laptop use. For mobile, the Google AI Edge Eloquent app supports native offline use with Gemma 4 12B. Developer pipelines are available through Hugging Face Transformers, llama.cpp, MLX, SGLang, and vLLM. Fine-tuning support is available via Unsloth.
05.Is Gemma 4 12B open source? What license does it use?
Yes. Gemma 4 12B is fully open and released under the Apache 2.0 license — one of the most permissive open-source licenses. You can use the model for commercial applications, modify the weights, and distribute your work without paying royalties, subject to the Apache 2.0 terms.
06.What is Multi-Token Prediction (MTP) and how does it speed up Gemma 4 12B?
Multi-Token Prediction (MTP) is a speculative decoding technique where a smaller 'drafter' model predicts multiple future tokens simultaneously. Gemma 4 12B ships with built-in MTP drafters that reduce token generation latency in real-world inference by up to 30–50% on supported hardware. This is especially beneficial for agentic workflows that require long, multi-step reasoning outputs.
07.How does Gemma 4 12B compare to the Gemma 4 26B MoE model in benchmarks?
Google states that Gemma 4 12B delivers performance 'nearing' the 26B Mixture of Experts (MoE) model on standard benchmarks, while having less than half the total memory footprint. The 26B MoE model, being a sparse architecture, uses more total parameters but activates only a subset per forward pass. Gemma 4 12B uses a dense 12B architecture — simpler to quantize, run, and fine-tune locally.